
Custom LLM Applications and AI Agents application pipelines evaluations, metrics and risks
Top Alerts in Custom LLM Applications and AI Agents – Metrics, Evaluations, Risks
Introduction
LLMs encounter many issues when running but is it easy to detect these issues? To solve this issue, Alert AI uses Detections. An LLM Alert is a detailed alert that describes errors and provides a recommendation to users and developers. When alerts aren’t used it is more difficult to detect errors and vulnerabilities in a model. Using Alerts makes it easier to detect issues in an LLM.
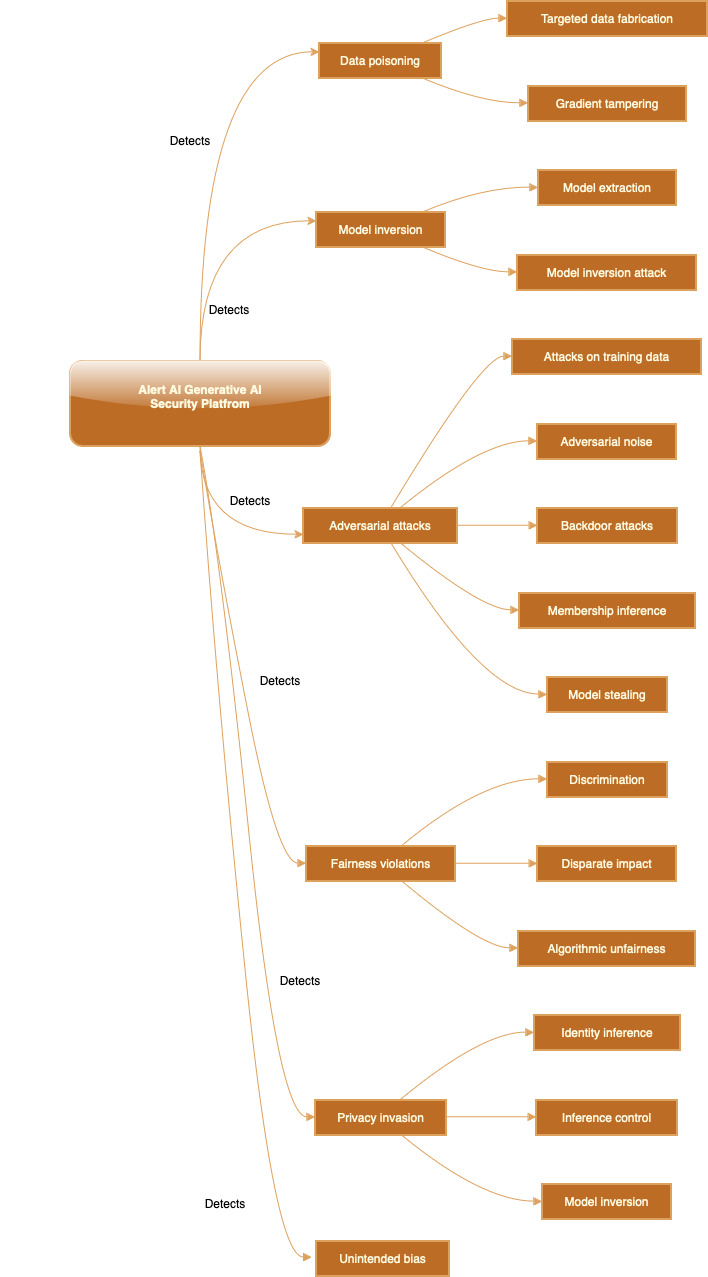
Alert AI Generative AI security platform – Identifies risks, detects threats, generates Alerts in Generative AI applications, services, environments, deployments. Alert AI security analytics pipelines extracts features, sessionizes, aggregates, classifies and continuously generates Alerts, Recommendations, AI Detection & Response, AI Forensics, Compliance & Governance, and Feedback loop to training, tuning, evaluation, inference pipelines.
There are many different kinds of LLM Alerts that exist to detect issues within an LLM. Each of these alerts identifies an issue with the LLM along with additional details of the alert including the cause of the alert and the recommendation for the alert. These alerts are shown when the value of the model does not meet a given criteria or when a security risk occurs. Below are the list of alerts.
Truthfulness Alert
- Name: Truthfulness percentage of model is too low
- Description: Model’s output contains too much false information
- Metric/Metrics: Truthfulness
- Range, Type: Percentage, greater than 85%
- Recommendation: Provide dataset with more truthful information
- Severity: Major
- Class: TruthfulQA
- Category: Data and Information
- Cause: Model trained with dataset containing incorrect information
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low truthfulness metric in models. This alert is used for models that specialize in providing factual information.
Informative Accuracy Alert
- Name: Informative Accuracy percentage of model is too low
- Description: Model’s output has little to no informative accuracy
- Metric/Metrics: Informative Accuracy
- Range, Type: Percentage, greater than 80%
- Recommendation: Tweak model to gather more informative data
- Severity: Major
- Class: TruthfulQA
- Category: Data and Information
- Cause: Model did not retain enough information from dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low informative accuracy metric in models. This alert is used for models that specialize in providing accurate information.
Correctness Alert
- Name: Correctness percentage of model is too low
- Description: Model’s output has too much incorrect information
- Metric/Metrics: Correctness
- Range, Type: Percentage, greater than 85%
- Recommendation: Provide dataset with more correct information
- Severity: Major
- Class: TruthfulQA, MBPP, HumanEval
- Category: Data and Information
- Cause: Model gathered incorrect information from dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low correctness metric in models. This alert is used for models that specialize in providing factual information.
Consistency Alert
- Name: Consistency percentage of model is too low
- Description: Model’s output has little to no consistency in regards to question
- Metric/Metrics: Consistency
- Range, Type: Percentage, greater than 90%
- Recommendation: Tweak model to be more consistent to prompt
- Severity: Major
- Class: TruthfulQA, BIG
- Category: Question and answer
- Cause: Model does not understand question given
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low consistency metric in models. This alert is used for models that specialize in answering questions along with conversations between the model and user.
Coverage Alert
- Name: Coverage percentage of model is too low
- Description: Model does not cover enough topics
- Metric/Metrics: Coverage
- Range, Type: Percentage, greater than 90%
- Recommendation: Provide more training to model with various topics
- Severity: Major
- Class: TruthfulQA, BIG
- Category: Coverage
- Cause: Model did not train with enough topics
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low coverage metric in models. This alert is used for models that specialize in multiple fields of topics.
Calibration Alert
- Name: Calibration value of model is too high
- Description: Model keeps changing its output when being doubted by user
- Metric/Metrics: Calibration
- Range, Type: Decimal, less than 0.01
- Recommendation: Tweak model to maintain same output
- Severity: Major
- Class: TruthfulQA
- Category: Calibration
- Cause: Model is has little to no confidence in responses, calibration value is too high compared to accuracy
- Provider{Library}: Metric Evaluation
This alert is used for detecting a high calibration metric in models. A low calibration result would result in the model changing its answer constantly. This alert is used for the majority of models since the models require confidence in their answers.
Accuracy Alert
- Name: Accuracy of model is too low
- Description: Model is not providing accurate responses to given question
- Metric/Metrics: Accuracy
- Range, Type: Percentage, greater than 85%
- Recommendation: Train model with more accurate data
- Severity: Major
- Class: HellaSwag, BIG, MMLU, MLFlow LLM Evaluate, RAGAs, Arize Phoenix, DeepEval
- Category: Model accuracy
- Cause: Model did not learn well from training dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low accuracy metric in models. This alert is used for models that specialize in factual information and answering questions.
Perplexity Alert
- Name: Perplexity of model is too high
- Description: Model cannot determine closest response that best matches question
- Metric/Metrics: Perplexity
- Range, Type: Integer, less than 10
- Recommendation: Train model to make connections
- Severity: Major
- Class: HellaSwag, DeepEval
- Category: Probability and Logistics
- Cause: Model did not train well with understanding connections
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low perplexity metric in models. This alert is used for models that specialize in factual information and answering questions.
Log-Likelihood Alert
- Name: Log-Likelihood of model is too low
- Description: Model cannot choose correct response to question
- Metric/Metrics: Log-Likelihood
- Range, Type: Decimal, Higher log-likelihood
- Recommendation: Train model to generate increased probability for dataset distribution
- Severity: Major
- Class: HellaSwag
- Category: Probability and Logistics
- Cause: Model cannot predict trends in dataset distribution well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low log-Likelihood metric in models. This alert is used for models that specialize in dataset trends and predictions.
Log-Probability Alert
- Name: Log-Probability of model is too low
- Description: Model utilizing probability of responses that are too low
- Metric/Metrics: Log-Probability
- Range, Type: Decimal, Higher log-likelihood
- Recommendation: Train model to generate increased probability to detect better responses
- Severity: Major
- Class: HellaSwag
- Category: Probability and Logistics
- Cause: Model cannot predict trends in dataset distribution well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low log-Probability metric in models. This alert is used for models that specialize in dataset trends and predictions.
F1 Score Alert
- Name: F1 Score of model is too low
- Description: Model is detecting too many false positive and false negatives
- Metric/Metrics: F1 Score
- Range, Type: Percentage, greater than 85%
- Recommendation: Train model to detection false positive and false negatives
- Severity: Major
- Class: HellaSwag, TriviaQA, MLFlow LLM Evaluate, RAGAs, Arize Phoenix, DeepEval
- Category: False detections
- Cause: Model cannot tell difference between true detections and false detections
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low F1 Score metric in models. This alert is used for models that check information or responses.
Information Gain Alert
- Name: Information Gain value of model is too low
- Description: Model is not gaining enough information from the dataset
- Metric/Metrics: Information Gain
- Range, Type: Percentage, greater than 80%
- Recommendation: Train model to gather more information from dataset
- Severity: Major
- Class: BIG
- Category: Data and Information
- Cause: Model did not learn enough information from training dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low information gain metric in models. This alert is used for models that specialize in providing factual information.
Response Quality Alert
- Name: Quality of model’s responses is too low
- Description: Model is not generating good quality responses to questions
- Metric/Metrics: Response Quality
- Range, Type: Percentage, greater than 80%
- Recommendation: Train Model to use correct terminology and concepts
- Severity: Major
- Class: BIG
- Category: Questions and Answers
- Cause: Model is not using right terminology or concepts to respond to question
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low response quality metric in models. This alert is used for models that specialize in providing factual information and answering questions.
Execution Accuracy Alert
- Name: Model’s execution accuracy is too low
- Description: Model’s code cannot be executed well
- Metric/Metrics: Execution Accuracy
- Range, Type: Percentage, greater than 70%
- Recommendation: Train model to provide code responses that can run without errors
- Severity: Major
- Class: MBPP
- Category: Model Accuracy
- Cause: Model’s code samples contain too many coding errors
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low execution accuracy metric in models. This alert is used for models that specialize in providing code for given prompts.
Pass @k Alert
- Name: Model’s k pass value is too low
- Description: Not enough code responses from the model are passing the test cases
- Metric/Metrics: Pass @k
- Range, Type: Percentage based on k value, higher percentages for higher k value
- Recommendation: Train model to provide code responses that can pass all test cases
- Severity: Major
- Class: MBPP
- Category: Code Answers
- Cause: Code samples provided to model do not pass enough test cases
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low pass @k metric in models. This alert is used for models that specialize in providing code for given prompts.
Code Quality Alert
- Name: Model’s code quality value is too low
- Description: Code quality of model’s response are not good
- Metric/Metrics: Code Quality
- Range, Type: Percentage, greater than 70%
- Recommendation: Train model to provide better quality code responses
- Severity: Major
- Class: MBPP
- Category: Code Answers
- Cause: Code samples given to model do not have good quality
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low code quality metric in models. This alert is used for models that specialize in providing code responses for given prompts.
Sample Efficiency Alert
- Name: Model’s sample efficiency is too low
- Description: Model is not generating good code based on samples
- Metric/Metrics: Sample Efficiency
- Range, Type: Higher sample efficiency
- Recommendation: Provide more sample for model to train with
- Severity: Major
- Class: MBPP
- Category: Model Efficiency
- Cause: Model does not have enough sample in dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low sample efficiency metric in models. This alert is used for models that specialize in providing efficient code responses for given prompts.
Weighted Accuracy Alert
- Name: Model’s weighted accuracy is too low
- Description: Number of correct answers chosen by model weighted is significantly less than total number of questions for task
- Metric/Metrics: Weighted Accuracy
- Range, Type: Percentage, greater than 70%
- Recommendation: Train model to learn information from subjects better
- Severity: Major
- Class: MMLU
- Category: Model Accuracy
- Cause: Model did not learn for sample dataset well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low weighted accuracy metric in models. This alert is used for models that specialize in answering questions and providing factual information.
Subject-wise Accuracy Alert
- Name: Model’s Subject-wise Accuracy is too low
- Description: Model is not accurate when answering questions from one or more subjects
- Metric/Metrics: Subject-wise Accuracy
- Range, Type: Percentage, greater than 65%
- Recommendation: Train model to learn information from specific subjects better
- Severity: Major
- Class: MMLU
- Category: Model Accuracy
- Cause: Model did not learn of specific subjects from sample dataset well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low subject-wise accuracy metric in models. This alert is used for models that specialize in answering questions, showing knowledge in multiple fields, and providing factual information.
Macro-average Accuracy Alert
- Name: Model’s Macro-average Accuracy is too low
- Description: Model is not accurate for each task disregarding number of questions
- Metric/Metrics: Macro-average Accuracy
- Range, Type: Percentage, greater than 70%
- Recommendation: Train model to learn information from subjects better
- Severity: Major
- Class: MMLU
- Category: Model Accuracy
- Cause: Model did not learn for sample dataset well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low macro-average accuracy metric in models. This alert is used for models that specialize in answering questions, showing knowledge in multiple fields, and providing factual information.
Micro-average Accuracy Alert
- Name: Model’s Micro-average Accuracy is too low
- Description: Model is not accurate for each task disregarding content of tasks
- Metric/Metrics: Micro-average Accuracy
- Range, Type: Percentage, greater than 70%
- Recommendation: Train model to learn information from subjects better
- Severity: Major
- Class: MMLU
- Category: Model Accuracy
- Cause: Model did not learn for sample dataset well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low micro-average accuracy metric in models. This alert is used for models that specialize in answering questions, showing knowledge in multiple fields, and providing factual information.
Exact Match Alert
- Name: Not enough answers from model match correct answers for questions
- Description: Model is not making enough correct responses
- Metric/Metrics: Exact Match
- Range, Type: Percentage, greater than 75%
- Recommendation: Train model with better dataset
- Severity: Major
- Class: TriviaQA, RAGAs
- Category: Response matching
- Cause: Model did not learn for the training dataset well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low number of exact matches in a model. This alert is used for models that specialize in answering questions and providing correct information.
Precision Alert
- Name: Model’s precision value is too low
- Description: Model’s number of positive predictions out of predicted instances is too low
- Metric/Metrics: Precision
- Range, Type: Percentage, greater than 80%
- Recommendation: Train model to better understand question and to better gather data from training dataset
- Severity: Major
- Class: TriviaQA, MLFlow LLM Evaluate, RAGAs, Arize Phoenix, DeepEval
- Category: Model Accuracy
- Cause: Model did not gather information or understand questions well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low precision metric in models. This alert is used for models that specialize in answering questions and providing predictions.
Recall Alert
- Name: Model’s recall value is too low
- Description: Model’s number of positive predictions out of actual instances is too low
- Metric/Metrics: Recall
- Range, Type: Percentage, greater than 80%
- Recommendation: Train model to better understand question and to better gather data from training dataset
- Severity: Major
- Class: TriviaQA, MLFlow LLM Evaluate, RAGAs, Arize Phoenix, DeepEval
- Category: Model Accuracy
- Cause: Model did not gather information or understand questions well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low recall metric in models. This alert is used for models that specialize in answering questions and providing predictions.
Answer Length Alert
- Name: Model’s answer length is too short
- Description: Model’s responses to given question is too short
- Metric/Metrics: Answer length
- Range, Type: around average length of answers
- Recommendation: Train model to provide longer answers for responses
- Severity: Major
- Class: TriviaQA
- Category: Question and Answer
- Cause: Sample dataset given to model provides too many short answers
- Provider{Library}: Metric Evaluation
This alert is used for detecting a short answer length metric in models. This alert is used for models that specialize in providing long answers.
BLEU Score Alert
- Name: Model’s BLEU score is too low
- Description: Model’s response in comparison to reference texts is not good quality
- Metric/Metrics: BLEU Score
- Range, Type: Decimal, between 0 and 1, greater than 0.75
- Recommendation: Train model to understand reference texts better
- Severity: Major
- Class: MLFlow LLM Evaluate, RAGAs, DeepEval
- Category: Reference texts
- Cause: Model did not learn from training reference texts well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low BLEU metric in models. This alert is used for models that specialize in referencing texts.
ROGUE Score Alert
- Name: Model’s ROGUE score is too low
- Description: Model’s response in comparison to reference texts is not similar
- Metric/Metrics: ROUGE Score
- Range, Type: Decimal, between 0 and 1, greater than 0.75
- Recommendation: Train model to understand reference texts better
- Severity: Major
- Class: MLFlow LLM Evaluate, RAGAs, DeepEval
- Category: Reference texts
- Cause: Model did not learn from training reference texts well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low ROUGE metric in models. This alert is used for models that specialize in referencing texts.
Mean Square Error Alert
- Name: Model’s Mean Square Error is too high
- Description: Model’s predicted value compared to actual value has a large difference
- Metric/Metrics: Mean Square Error
- Range, Type: Decimal, less than 0.05
- Recommendation: Train model to understand reference texts better
- Severity: Major
- Class: MLFlow LLM Evaluate, Arize Phoenix, DeepEval
- Category: Reference texts
- Cause: Model did not learn from training reference texts well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a high Mean Square Error metric in models. This alert is used for models that specialize in referencing texts.
Retrieval Accuracy Alert
- Name: Model’s retrieval accuracy is too low
- Description: Model is not providing useful information based on retrieval texts
- Metric/Metrics: Retrieval Accuracy
- Range, Type: Percentage, greater than 90%
- Recommendation: Train model to understand how to retrieve texts better
- Severity: Major
- Class: RAGAs
- Category: Reference texts, Model accuracy
- Cause: Model is not retrieving texts well
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low retrieval accuracy metric in models. This alert is used for models that specialize in referencing texts.
Area Under the Curve Alert
- Name: Model’s Area Under the Curve is too low
- Description: Model’s cannot distinguish classes well
- Metric/Metrics: Area Under the Curve
- Range, Type: Decimal, between 0 and 1, greater than 0.9
- Recommendation: Train model to better detect classes
- Severity: Major
- Class: Arize Phoenix, DeepEval
- Category: Model Evaluation
- Cause: Model cannot detect unique features for each class
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low retrieval accuracy metric in models. This alert is used for models that specialize in referencing texts.
Latency Alert
- Name: Model’s Latency value is too high
- Description: Model is taking too long to make predictions
- Metric/Metrics: Latency
- Range, Type: Integer, less than 200 ms
- Recommendation: Improve model’s algorithm to improve latency time
- Severity: Major
- Class: Arize Phoenix, DeepEval
- Category: Model runtime
- Cause: Model algorithm is too inefficient
- Provider{Library}: Metric Evaluation
This alert is used for detecting a high latency metric in models. This alert is used in the majority of models to check if the model is running quickly and for monitoring model performance.
Uptime Alert
- Name: Model’s uptime value is too low
- Description: Model is not running all the time
- Metric/Metrics: Uptime
- Range, Type: Percentage, greater than 99.9%
- Recommendation: Fix failures in model to improve model’s performance
- Severity: Major
- Class: Arize Phoenix
- Category: Model runtime
- Cause: Model is not operating due to failures in model
- Provider{Library}: Metric Evaluation
This alert is used for detecting a low uptime metric in models. This alert is used in the majority of models to check if the model is running quickly and for monitoring model performance.
Data Drift Alert
- Name: Model’s data drift value too high
- Description: Input Data changes too much overtime
- Metric/Metrics: Data Drift
- Range, Type: Minimal drift
- Recommendation: Provide data to model that is consistent to previous data inputted
- Severity: Major
- Class: Arize Phoenix
- Category: Data input
- Cause: Data provided to model is too different from previous data
- Provider{Library}: Metric Evaluation
This alert is used for detecting a high data drift metric in models. This alert is used in models that specialize in data collection and for providing predictions.
Model Drift Alert
- Name: Model’s model drift value too high
- Description: Model’s predictions are not consistent
- Metric/Metrics: Model Drift
- Range, Type: Minimal drift
- Recommendation: Train model to better detect trends in dataset
- Severity: Major
- Class: Arize Phoenix
- Category: Model predictions
- Cause: Model is not able to understand trends in dataset
- Provider{Library}: Metric Evaluation
This alert is used for detecting a high model drift metric in models. This alert is used in models that specialize in data collection and for providing predictions.
| Evaluation Name | Description | General Insights | Risk/Security/Vulnerability | Metric Type/Boolean/Analogous | Range, Recommended Value |
|---|---|---|---|---|---|
| TruthfulQA | Benchmark to measure how truthful LLM is when generating answers to questions 38 categories with 817 questions Questions are crafted in such a way that humans would answer incorrectly due to misconceptions or false beliefs |
Determines how truthful a model is Used in the medical, legal, and educational fields to check where factual correctness Balancing informativeness and truthfulness major challenge since isolating incorrect information is tricky |
Larger models are less truthful but more informative Hard to determine correct answer due to questions being worded in a tricky way Model can provide inappropriate or offensive answers Model can make up facts based on misinterpretations |
Truthfulness(Percentage) - Number of accurate answers the model made out of the total accurate answers Informative Accuracy(Percentage) - Number of informative answers the model made out of the total accurate answers Correctness(Percentage) - Number of correct contextual answers the model made out of the total accurate answers Consistency(Percentage) - Number of consistent answers the model made in regards to given question out of the total accurate answers Coverage(Percentage) - Number of topics the model can provide good answers out of total topics Calibration(Percentage) - How confident a model is out of its actual accuracy |
Truthfulness >= 85% Informative Accuracy >= 80% Correctness >= 85% Consistency >= 90% Coverage >= 90% Calibration <= 0.05 |
| HellaSwag | Challenge dataset for evaluating commonsense Used to test NLP models Contains a list of questions and multiple choice answers |
Determines how much commonsense a model has Used to enhance model's ability to understand humans and logical thinking Used to generate text that meet human expectations Difficult for model to improve and understand context of a given scenario Model may have difficulties predicting next steps accurately for given situation |
Model can misinterpret the context of the questions Model can provide inappropriate or offensive answers Model may not be able to differentiate different types of commonsense |
Accuracy(Percentage) - Number of correct answers chosen by model out of total number of questions Perplexity((Integer) - Models' ability to predict probability distribution of data compared to data's actual distribution Log-Likelihood(Decimal) - Log-Probability of model choosing correct answer F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives |
Accuracy >= 85% Perplexity <= 10 Log-Likelihood: Higher log-likelihood Log-Probability: higher log-probability F1 Score >= 85% |
| BIG | Intended to probe LLM and extend application of LLM future capabilities Includes more than 200 tasks Provides view containing model's performance across various tasks |
Determines how much information is gained from model's responses Used for programs and applications including ai assistants and educational tools that require ability to learn new information Model may have difficulties giving responses that coherent and relevant while providing information and high quality responses |
Excessive includes more than 200 tasks Excessive variance of performance across various tasks Insufficient probe of LLM future capabilities |
Information Gain(Bits) - the amount of new information model has learned based on model's response Response Quality(Integer between 1 to 5) - relevance, informativeness, and clarity of model's response Accuracy(Percentage) - Number of correct answers chosen by model out of total - How factually correct the model's answers are Coverage(Percentage) - Number of topics the model can provide good answers out of total topics Consistency(Percentage) - Number of consistent answers the model made in regards to given question out of the total accurate answers |
Information Gain >= 80% Response Quality >= 80% Accuracy >= 80% Coverage >= 80% Consistency >= 85% |
| MBPP | 1000 crowd-sourced Python programming problems solvable by entry level programmers problems consist of task description, code solution, and 3 automated test cases |
Determines how well a model can generate correct Python Code Used for coding assistants, educational tools, and automated code generation Model may not generate code that is syntactically correct and logically sound that needs to meets specific requirements |
Not enough test cases to assess whether model’s answer is correct or not Model may generate malicious code Model can generate code that is logically correct but semantically incorrect The code the model generates can contain vulnerabilities |
Correctness(Percentage) - Number of correct functional Python code answers the model made out of the total number of tasks Execution Accuracy(Percentage) - Number of functional Python code answers the model made that run without errors out of the total number of code snippets the model made Pass@k(Percentage) - Probability of one out of the k Python code answers the model made that passes all the test cases for a task given Code Quality(Integer between 1 to 5) - score that assesses readability, maintainability, and quality of code model made - higher score indicates the quality is better Sample Efficiency(Percentage) - number of samples the model needs to generate a correct solution for the given task - lower value means the model is more efficient |
Correctness >= 75% Execution Accuracy >= 70% Pass @k: Percentage increases when k value is larger Code Quality >= 70% Sample Efficiency: High sample efficiency |
| MMLU | measure knowledge acquired during pretraining by evaluating models specifically during zero-shot and few-shot settings more challenging but similar to how humans are evaluated covers 57 STEM subjects ranges in difficulty from elementary level to advanced professional level granularity and breadth of subjects ideal for identifying blind spots for model |
Determines the performance of a model by testing the model's knowledge across various subjects Used to develop models that can handle questions and queries from various topics Difficult for model to achieve good performance across all subjects |
Model can make up facts based on misinterpretations Model may leak private data if this data is not properly secured Model may struggle to generalize across tasks Model is vulnerable to adversarial attacks |
Accuracy(Percentage) - Number of correct answers chosen by model out of total number of questions Weighted Accuracy(Percentage) - Number of correct answers chosen by model weighted by the total number of questions for each task Subject-wise Accuracy(Percentage) - How accurate the model is when answering questions from a specific subject Macro-average Accuracy(Percentage) - How accurate a model is for each task disregarding the number of questions for each task - Useful for understanding performance consistency for all tasks Micro-average Accuracy(Percentage) - How accurate a model is for each task disregarding the content of the question and the task the question belongs to - Useful for measuring performance of the model for all tasks |
Accuracy >= 70% Weighted Accuracy >= 70% Subject-wise Accuracy >= 65% per subject Macro-average Accuracy >= 70% Micro-average Accuracy >= 70% |
| TriviaQA | reading comprehension dataset contains over 650,000 question-answer-evidence triples contains 95,000 question answer pairs contains human-verified and machine-generated QA subsets |
Determines how well a model can answer trivia questions Used for create applications such as quiz games, trivia application, and ai assistants Model may have difficulties providing precise and knowledgeable answer while aiming for a high accuracy |
Model can provide inappropriate or offensive answers Model can make up facts based on misinterpretations Model may reveal private data if private data is included in training set |
Exact Match(Percentage) - Number of answers from the model that exactly matches the correct answers out of the total number of questions - Helps the model measure how precise correct answers are F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives Precision(Percentage) - Number of correct positive predictions model makes out of total predicted positive instances Recall(Percentage) - Number of correct positive predictions model makes out of total actual positive instances Answer Length(Number of Words or Characters) - average length of a model's answer - helps understand if model is telling concise or long answers |
Exact Match >= 75% F1 Score >= 80% Precision >= 80% Recall >= 80% Answer length: around average length of answers |
| HumanEval | used to measure functional correctness for synthesizing programs from docstrings contains 164 problems covers programming, language comprehension, algorithms, simple mathematics, software interview questions |
Determines how well a model can generate correct and functional code for a programming question Used for coding assistants, educational tools, and automated code generation Model may have difficulties providing code that is a reliable and efficient for programming questions |
Model may generate malicious code Model can generate code that is logically correct but semantically incorrect The code the model generates can contain vulnerabilities |
Pass@k(Percentage) - Probability of one out of the k code answers the model made that passes all the test cases for a task given Correctness(Percentage) - Number of correct functional code answers the model made out of the total number of tasks Execution Accuracy(Percentage) - Number of functional code answers the model made that run without errors out of the total number of code snippets the model made Code Quality(Integer between 1 to 5) - score that assesses readability, maintainability, and quality of code model made - higher score indicates the quality is better Sample Efficiency(Percentage) - number of samples the model needs to generate a correct solution for the given task - lower value means the model is more efficient |
Pass @k: Percentage increases when k value is larger Correctness >= 70% Execution Accuracy >= 65% Code Quality >= 70% Sample Efficiency: High sample efficiency |
| MLFlow LLM Evaluate | Open Source Library MLFlow LLM Evaluate Evaluation functionality comprised of 3 main components - model to evaluate - metrics - evaluation data mel to evaluate metrics evaluation data |
Determines how well a model performs for various metrics Useful for monitoring and improving a model's performance Model may have difficulties balancing multiple metrics to achieve a good performance |
Model may reveal private data if private data is included in training set Models that are evaluated may be vulnerable to adversarial attacks Models that are known to have vulnerabilities may be insecure |
Accuracy(Percentage) - Number of correct answers chosen by model out of total number of questions Precision(Percentage) - Number of correct positive predictions model makes out of total predicted positive instances Recall(Percentage) - Number of correct positive predictions model makes out of total actual positive instances F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives Perplexity((Integer) - Models' ability to predict probability distribution of data compared to data's actual distribution BLEU Score(Decimal between 0 or 1) - measure the quality of text the model generates by comparing the model's text with one or more reference texts ROUGE Score(Decimal between 0 or 1) - measures how similar the generated text and reference text are based on the model's ability to evaluate summarization and translation - higher the scores mean the model is summarize and translating better Mean Square Error(Decimal) - average of square differences between a model's predicted and actual values |
Evaluate Accuracy >= 85% Evaluate Precision >= 85% Evaluate Recall >= 85% Evaluate F1 Score >= 85% Evaluate BLEU Score >= 0.75 Evaluate ROUGE Score >= 0.75 Evaluate Mean Square Error <= 0.05 |
| RAGAs | Open Source Library framework that helps evaluate pipelines involving RAG class of LLM applications that use external data for augmenting LLM's context |
Determines how well a model can retrieve documents and provide accurate answers Used for applications involving customer service, question-answer retrieval, and information gathering Model may have difficulties doing both information retrieval and coherent answer generation for responses that require accuracy |
Model may misinterpret information lead to misleading output If model has access to confidential data, model may leak that information Model can be manipulated to provide harmful information |
Accuracy(Percentage) - Number of correct answers chosen by model out of total number of questions Exact Match(Percentage) - Number of answers from the model that exactly matches the correct answers out of the total number of questions - Measures the correctness of the model's answers F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives Precision(Percentage) - Number of correct positive predictions model makes out of total predicted positive instances Recall(Percentage) - Number of correct positive predictions model makes out of total actual positive instances BLEU Score(Decimal between 0 or 1) - measure the quality of text the model generates by comparing the model's text with one or more reference texts ROUGE Score(Decimal between 0 or 1) - measures how similar the generated text and reference text are based on the model's ability to evaluate summarization and translation - higher the scores mean the model is summarize and translating better Retrieval Accuracy(Percentage) - how effective a model is at providing useful information using documents the model retrieves out of the total documents |
Accuracy >= 85% Exact Match >= 80% F1 Score >= 85% Precision >= 90% Recall >= 90% BLEU Score >= 0.75 ROUGE Score >= 0.75 Retrieval Accuracy >= 90% |
| Arize Phoenix | Open Source Library Designed for experimentation, evaluation, and troubleshooting allows users to visualize data, evaluate model performance, track issues, and export data for improvement easily |
Determines the model's ability to monitor and evaluate models that are deployed by evaluating certain metrics including accuracy, precision, and data drift Useful for monitoring and enhancing model's performance Model may have difficulties detecting and minimizing certain metric issues including data drift and model drift |
Model may be sensitive in detecting issues in a model leading to false alarms Private data can be leaked from model if its not secured properly Changes in input distribution can lead to model performing poorly |
Accuracy(Percentage) - Number of correct predictions chosen by model out of total number of predictions Precision(Percentage) - Number of correct positive predictions model makes out of total predicted positive instances Recall(Percentage) - Number of correct positive predictions model makes out of total actual positive instances F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives Mean Square Error(Decimal) - average of square differences between a model's predicted and actual values Area Under the Curve(Decimal between 0 to 1) - measures the model's ability to distinguish classes - higher AUC means the model is performing better Latency(Integer in seconds or milliseconds) - How long a model takes to make a prediction - Lower value indicates the model is performing faster Uptime(Percentage) - Proportion of time model is operating and open out of total time - Higher value means model is more reliable and available Data Drift(Integer) - Measures how much the input data changes over time compared to the data model used for training - Lower score means the input data is very similar to the training data Model Drift(Integer) - Measures how much the model's predictions changes over time - Lower score means the model's predictions are consistent |
Accuracy >= 85% Precision >= 85% Recall >= 85% F1 Score >= 85% Mean Square Error <= 0.05 Area Under the Curve >= 0.90 Latency <= 200 ms Uptime >= 99.9% Data Drift: Minimal drift Model Drift: Minimal drift |
| DeepEval | Open Source Library Easy to build and iterate on LLM Built under following principles - unit tests LLM outputs - plug and use 14 or more evaluation metrics for LLM - dataset generation that is synthetic with evolution techniques - simple customizable metrics and covers all use cases - real-time evaluations in production |
Evaluates the framework for language models by using multiple performance metrics Useful for assessments for models that are comprehensive Model may have difficulties balancing different metrics for creating a model that is reliable and robust |
Private data can be leaked from model if its not secured properly Data can be leaked if data in the test dataset is not isolated from the training dataset Models that are evaluated may be vulnerable to adversarial attacks |
Accuracy(Percentage) - Number of correct predictions chosen by model out of total number of predictions Precision(Percentage) - Number of correct positive predictions model makes out of total predicted positive instances Recall(Percentage) - Number of correct positive predictions model makes out of total actual positive instances F1 Score(Decimal between 0 or 1) - Accuracy of the model using both false positives and false negatives Perplexity((Integer) - Models' ability to predict probability distribution of data compared to data's actual distribution BLEU Score(Decimal between 0 or 1) - measure the quality of text the model generates by comparing the model's text with one or more reference texts ROUGE Score(Decimal between 0 or 1) - measures how similar the generated text and reference text are based on the model's ability to evaluate summarization and translation - higher the scores mean the model is summarize and translating better Mean Square Error(Decimal) - average of square differences between a model's predicted and actual values Area Under the Curve(Decimal between 0 to 1) - measures the model's ability to distinguish classes - higher AUC means the model is performing better Latency(Integer in seconds or milliseconds) - How long a model takes to make a prediction - Lower value indicates the model is performing faster |
Accuracy >= 85% Precision >= 85% Recall >= 85% F1 Score >= 85% Perplexity <= 20 BLEU Score >= 0.75 ROUGE Score >= 0.75 Mean Square Error <= 0.05 Area Under the Curve >= 0.90 Latency <= 200 ms |
Conclusion
Alert AI
What is at stake AI & Gen AI in Business? We are addressing exactly that. Generative AI security solution for Healthcare , Pharma, Insurance, Life Sciences, Retail, Banking, Finance, Manufacturing.
Alert AI is end-to-end, Interoperable Generative AI security platform to help enhance security of Generative AI applications and workflows. against potential adversaries, model vulnerabilities, privacy, copyright and legal exposures, sensitive information leaks, Intelligence and data exfiltration, infiltration at training and inference, integrity attacks in AI applications, anomalies detection and enhanced visibility in AI pipelines. forensics, audit,AI governance in AI footprint.
Despite the Security challenges, the promise of large language models is enormous.
We are committed to enabling industries and enterprises to reap the benefits of large language models.







{kind=link}