
OWASP Top 10 LLM Security Measures
OWASP’s Top 10 LLM risks
Generative AI applications using LLM models, pose a new class of Risks and attack vector.
OWASP’s Top 10 LLM risks
OWASP is an Open Source Web Applications Security Project has formulated the standards,methodologies and documented the Top 10 LLM model threats for organizations to adopt,conceive and acquire the factors and to address the cybersecurity threats.
The objectives when followed assures that the threats are addressed and applications can operate safely and securely.
Alert AI
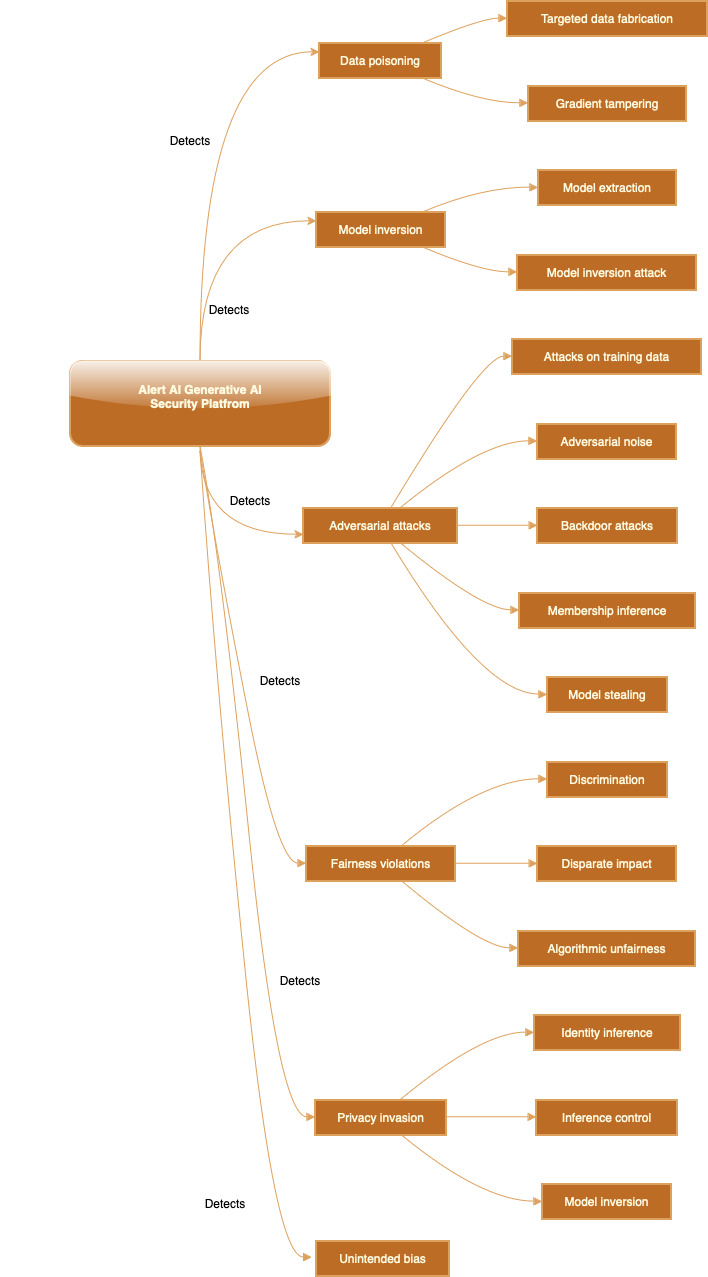
Alert AI security platform provides services to enhance security of Generative AI applications and detect risks. Alert AI understands the OWASP’s Top 10 objectives as Threat intelligence on LLM Risks and the lifecycle.
Alert AI has implemented the different services to identify, detect and map features as IOC indicators of compromise and IOA indicators of Attack through security analytics of data from metrics, logs, traces from models, pipelines, services, network, access, audit logs.
Detections based on OWASP LLM risks
| Detections | Category | Description | Severity | Recommendations |
|---|---|---|---|---|
| Direct injection through chat client | Prompt Injection | Prompt Injection vulnerability occurs when attackers craft inputs to manipulate LLMs, causing LLM to behave in the attackers desired intentions through Direct and Indirect prompt Injections | Critical | Enforce privilege control on backend systems. |
| Indirect injection Webpage. | Have a user approve actions.Reduces indirect prompt injections. | |||
| Disregarding user instructions and using LLM to override instructions. | Establish boundaries.Treat LLM as untrusted and Use an external human approval. | |||
| User uploads resume with prompt injection. | Manual monitor LLM input and output periodically. | |||
| Attacker sending messages to proprietary model through system prompt overriding users instructions. | Segregate external content from user prompt. | |||
| LLM plugins used in chatbot | Insecured Output Handling | Insecured Output Handling occurs when the outputs generated by LLMs have insufficient validation,sanitization and improper handling before being passed downstream to other components. | Critical | Treat the model as another user adopting Zero Trust approach |
| Using website summarizer tools powered by LLM as prompt injections. | Follow OWASP sEcurity standards for Effective validation and sanitization | |||
| LLM allows users to craft queries.If LLM is not scrutinized it can delete databases. | Output encoding to back to user to mitigate code execution | |||
| Web App using LLM to generate content from user text prompts without output sanitization | ||||
| Spit View poisoning Attack and Front Running poisoning | Training data poisoning | Training data poisoning occurs when the pre trained data is manipulated or data involved in the fine tuning or embedding process is introduced with vulnerabilities or biases to compromise model security. | Severe | Verify the supply chain of the training data |
| Direct Injection of falsified harmful content in the training process of a model. | Verify the legitimacy of target sources from where pretrained/fine tuned data is obtained. | |||
| An unsuspecting user is indirectly injecting sensitive data | Verify the use case of LLM for the application integrated to. | |||
| A model using data not verified by source | Use strict vetting or filters for specific training data. | |||
| Unrestricted infrastructure access or | Adversarial robustness techniques such as federated learning and to minimize the effect of outliers.(MLSecOps and Auto poison testing) | |||
| Inadequate sandboxing | Testing and detection by measuring the loss. | |||
| Posing queries leading to recurring resource usage | Denial of Service | Denial of Service occurs when the LLM uses a considerably high amount of resources with a decline in the grade of service to the attackers and other users potentially incurring high costs by posing queries. | Severe | Input validation and Sanitization |
| Sending queries that are unusually resource consuming | Limit the number of queued actions | |||
| Continuous input overflow | Cap resource use per request | |||
| Repetitive long inputs | Enforce APi rate limits to number of requests | |||
| Recursive context expansion | Continuously monitor the resource utilizations | |||
| Variable length input flood | Set strict input Limits based on LLMs context windows | |||
| Promote awareness among developers about potential DoS vulnerabilities |
||||
| Traditional third party vulnerability | Supply ChainVulnerabilities | Supply ChainVulnerabilities occur when the LLMs integrity is impacted in the pre trained data and or training dta,ML Models and deployment platforms leading to security breaches ,biased outcomes and system failures. | Severe | Carefully vet data sources and suppliers |
| Using vulnerable pre trained model for fine tuning | Only use reputable plugins | |||
| Use of poison crowd source data for training | ||||
| Understand and apply mitigations found in OWASP | ||||
| Using outdated or deprecated models | ||||
| Unclear T&Cs and data privacy policies | Maintain an up to date inventory of components | |||
| Use MLOps best practises and platform offerings secure model repositories | ||||
| Use model and code signing when using | ||||
| External models. | ||||
| Anomaly detections and external robustness tests. | ||||
| Implement sufficient monitoring to cover component and environment vulnerabilities | ||||
| Implement patching policy to mitigate vulnerable outdated components | ||||
| Regularly review and audit supplier Security and Access | ||||
| Unsuspecting legitimate user A exposed to other user data | Sensitive Information disclosure | Sensitive Information disclosure occurs sensitive information,proprietary algorithms are revealed through outputs generated by LLMs resulting in security breaches and privacy violations and disclosure of sensitive data and intellectual property. | Severe | Integrate adequate data sanitization and scrubbing techniques |
| Incomplete or improper filtration of sensitive data | Input robust validation methods | |||
| Overfitting or memorization of sensitive data | Apply the rule of least privilege so that a higher privilege user access to a model is not displayed to a low privilege user | |||
| Unintended disclosure of sensitive information | Apply strict access control methods | |||
| Access to external source is limited | ||||
| A plugin accepts a single text field instead of distinct input parameters. | Insecure Plugin Design | Insecure Plugin Design occurs when malicious requests are sent through LLM plugins and extensions that when enabled are called by the model and uncontrolled by the application resulting in unexpected behaviors including remote code execution. | Severe | Plugins should enforce strict parameterized input |
| A plugin accepts configuration strings instead of parameters. | Plugin should apply OWASP recommendations in ASVS | |||
| A plugin accepts plain SQL statements instead of parameters. | Plugins should be inspected and trusted thoroughly. | |||
| Improper authorization to plugin. | Plugins should use proper OAuth identities. | |||
| Requires manual user authorization. | ||||
| Excessive Functionality-An LLM Agent access to plugin with functions not intended for this operation. | Excessive Agency | Excessive Agency is a vulnerability enabling damaging actions to be performed in response to output generated by LLMs regardless of what is causing the LLMs to malfunction be it hallucination,confabulation, direct/indirect prompt injection. |
High | |
| Trialed LLM plugin used in development phase available to the LLM agent. | ||||
| A LLM plugin with open ended functionality fails to filter input instructions. | Limit the plugins that LLM agents are allowed to only call minimum necessary functions. | |||
| Avoid open ended functions and use plugins with more granularity. | ||||
| Excessive | ||||
| Permission | Limit the plugins/tools to implement only necessary functions. | |||
| -LLM application/plugin has access downstream with high privileges. | ||||
| Limit the permissions that LLM plugin/tools are granted to other systems. | ||||
| -LLM Plugin has permission on other systems that are not intended for the operation of this application. | ||||
| Track the user authorization and security scope to ensure the actions taken on behalf of the user have minimum privilege. | ||||
| Excessive | Implement authorization in downstream systems instead of relying on LLM | |||
| Autonomy | ||||
| -LLM application/ plugin fails to independently verify and approve high impact actions. | ||||
| Use human in the loop to control and approve actions | ||||
| LLM provides inaccurate information when stating it as authoritative. | Overreliance | Overreliance occurs when the LLM produces factually incorrect ,inappropriate or unsafe erroneous information in an authoritative manner leading to security breach ,misinformation,miscommunication,legal issues and reputational damage. |
High | Regularly monitor and review the outputs |
| Cross -check the LLM output with external sources | ||||
| LLM suggests insecure and faulty code leading to vulnerabilities | ||||
| Enhance the model with fine-tuning and embeddings to improve output quality | ||||
| Implement automatic validation mechanisms | ||||
| Break down complex task into manageable subtask | ||||
| Communicate the risk and limitations associated with LLM to users | ||||
| Build API and user interfaces that encourage responsible and safe use of LLMs. | ||||
| When using LLM in a development environment ensure safe coding guidelines. | ||||
| An attacker uses the vulnerabilities in the infrastructure in the organization to gain access to the LLM model. | Model Theft | Model Theft occurs when the proprietary model is exfiltrated and physically stolen and or weights copied and parameters extracted to create a functional equivalent by unauthorized access to LLMs by malicious actors. | Severe | Implement strong access control and strong authentication mechanisms |
| An insider threat scenario where a disgruntled employee leaks information. | Use a centralized model Inventory with authentication | |||
| Attacker queries the | Restrict LLM access to network resources, internal services and API. | |||
| Model API to create a shadow model | ||||
| Regularly monitor and audit access logs | ||||
| Bypassing input filtering techniques. | ||||
| Automate MLOPs deployment with governance and tracking | ||||
| Attack vector for functional model replication via prompts as a means to self instruct to generate synthetic training data. | Implement controls and mitigation strategies | |||
| Rate limiting of API calls where applicable | ||||
| Implement adversarial robustness training and physical security measures. | ||||
| Implement a watermarking framework into embedding and detection stages of LLM lifecycle. |








{kind=link}